Retrieval-Augmented Generation (RAG) has quickly become the standard architecture for enterprise AI applications.
Most teams focus on improving retrieval quality, embedding models, chunking strategies, and prompt engineering. Much less attention is given to a fundamental question:
Can you trust the data being retrieved?
Traditional RAG pipelines assume that anything returned from a vector database is safe and trustworthy. In practice, that assumption often breaks down.
Potential risks include:
- Prompt injection hidden inside documents
- Sensitive data exposure
- Unauthorized access to protected content
- Retrieval of stale or tampered information
- Lack of auditability around retrieved context
To address these challenges, we are open-sourcing the AetherGuard RAG Security Kit.
The goal is simple:
Add zero-trust retrieval governance to existing RAG systems without requiring changes to your vector database or embedding model.
Design Principles
The project was designed around a few principles:
- Vector database agnostic
- Embedding model agnostic
- Minimal integration effort
- Retrieval-first security
- Evidence-based auditing
The SDK acts as a lightweight client while security processing happens server-side.
This allows organizations to continue using Pinecone, Chroma, Weaviate, Qdrant, pgvector, OpenSearch, or other vector stores without changing their existing retrieval architecture.
What's Included
The AetherGuard RAG Security Kit provides a set of security controls that can be integrated into existing Retrieval-Augmented Generation (RAG) pipelines.
Prompt Injection Detection
Detects common prompt injection attempts embedded in retrieved content, including patterns such as:
- Ignore previous instructions
- Reveal system prompt
- Forget your rules
- Execute this instead
Uses semantic analysis rather than relying solely on keyword matching, enabling detection of paraphrased and indirect attacks.
PII Detection
Identifies sensitive information within retrieved content, including:
- Email addresses
- Phone numbers
- Credit card numbers
- National identification numbers
- Healthcare-related identifiers
Supports both masking and blocking workflows depending on organizational policy requirements.
Secrets Detection
Detects potentially exposed credentials and secrets, including:
- API keys
- AWS credentials
- JWT tokens
- Database connection strings
- Private keys
Helps prevent accidental disclosure of sensitive information through retrieved context.
Toxicity & Safety Checks
Screens retrieved content for potentially unsafe material, including:
- Hate speech
- Harassment
- Toxic language
- Unsafe content
Allows organizations to apply safety controls before content reaches downstream LLMs or end users.
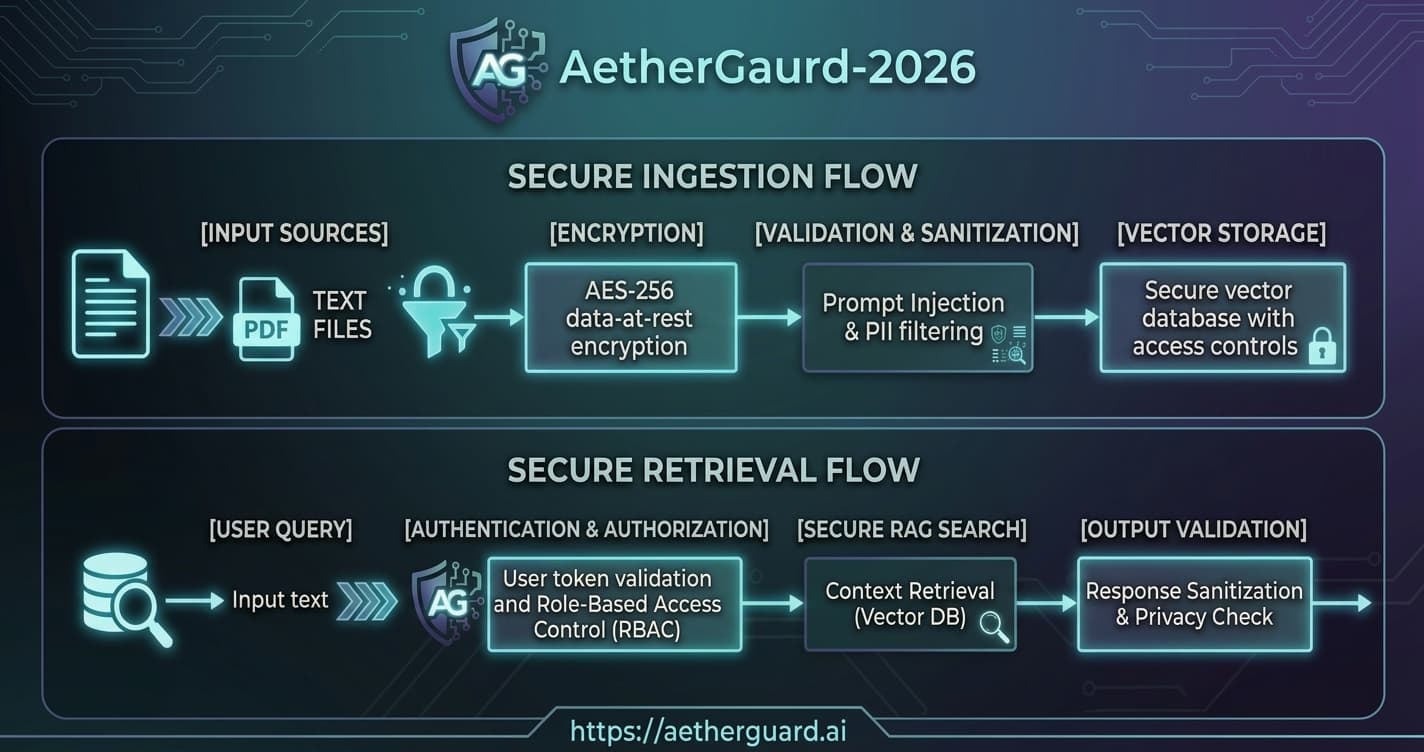
Secure Ingestion
During ingestion, document chunks and embeddings are submitted for security processing.
Metadata generated during ingestion can then be stored alongside vectors inside the vector database.
This creates a verifiable chain of trust between the original content and future retrieval operations.
Secure Retrieval
Instead of sending raw retrieval results directly to an LLM, applications can introduce a verification stage.
Retrieved chunks are evaluated before they become part of the model context.
This allows organizations to:
- Verify retrieval integrity
- Apply authorization policies
- Detect sensitive content exposure
- Sanitize unsafe context
- Generate evidence records for auditing
The objective is to ensure that only trusted context reaches the model.
Retrieval Integrity
One area that receives surprisingly little attention in RAG discussions is retrieval integrity.
Most security conversations focus on prompt injection.
However, if retrieved context has been altered, corrupted, incorrectly classified, or otherwise manipulated, downstream model behavior becomes unreliable regardless of prompt protections.
The RAG Security Kit introduces integrity verification mechanisms that allow applications to validate retrieved content before it is used for generation.
Authorization Before Retrieval
Another common pattern is querying a vector database first and checking permissions later.
A zero-trust approach reverses this process.
Applications can perform authorization checks before retrieval, ensuring users only access data they are permitted to retrieve.
This helps reduce accidental exposure of sensitive content and supports data governance requirements.
Auditability
Enterprise teams frequently ask:
- Which chunks were retrieved?
- Why were they allowed?
- Which policies were applied?
- What evidence exists for compliance reviews?
The project generates evidence records that can be used for auditing and investigation workflows.
Why Open Source?
We believe secure AI infrastructure should be easier to adopt.
Many teams already have functioning RAG systems but lack practical mechanisms for retrieval governance, integrity verification, and authorization controls.
By open-sourcing the SDK, developers can integrate these controls into existing pipelines without rebuilding their architecture.
Feedback Welcome
The project is still evolving, and we'd appreciate feedback from engineers building production RAG systems.
In particular, we're interested in discussions around:
- Retrieval integrity models
- Context verification approaches
- Authorization strategies
- Auditability requirements
- Security controls for large-scale RAG deployments
GitHub
GitHub repository: https://github.com/AetherGuardAI/aetherguard-rag-security-kit
GitHub: https://github.com/AetherGuardAI
Website: https://aetherguard.ai
Feedback, issues, feature requests, and contributions are welcome.